- target: [쿠버네티스 쉽게 이해하기 2] 쿠버네티스 아키텍처
- method:
2. 쿠버네티스 아키텍처 (Kubernetes Architecture)
쿠버네티스를 처음 설치하시는 분들은 가이드대로 따라하기는 하는데, 왜 이 작업을 해야 하는지 이해가 안되는 게 있을 겁니다.
그 궁금증들은 앞으로 과정을 진행하면서 자연스럽게 풀리게 될 겁니다.
쿠버네티스를 본격적으로 공부하기 전에 다른 제품들처럼 쿠버네티스도 아키텍처부터 이해할 필요가 있습니다.
먼저 쿠버네티스를 구성하는 컴포넌트들에 대해 이해하도록 하겠습니다.
컨테이너를 실행하고 관리하기 위해 어떻게 각 컴포넌트가 역할을 나눠서 하는지를 이해하면 이후에 쿠버네티스 리소스를 학습할 때 동작 원리가 좀 더 명확히 이해 됩니다.
두번째로 클러스터Cluster, 컨텍스트Context, 노드Node, 네임스페이스Namespace의 개념에 대해 배우도록 하겠습니다.
이 개념에 대해 이해하시면 어떤 원리로 클라이언트인 Bastion Node에서 서버인 쿠버네티스 클러스터로 연결이 되는지 알 수 있게 됩니다. 또한 여러개의 쿠버네티스 클러스터를 접근하는 방법도 아시게 될 겁니다.
2.1 쿠버네티스 컴포넌트(Kubernetes Component)
쿠버네티스 컴포넌트를 쉽게 이해하려면 프로젝트 수행 조직을 생각해 보면 됩니다.
프로젝트를 수행을 위한 역할은 PM(Project Manager-프로젝트 관리자), PMO(Proejct Management Officer-프로젝트 관리 감당자), PL(Part Leader-업무파트 담당자), 멤버로 구성 됩니다.
그리고 PMS(Project management System-프로젝트관리 시스템)를 통하여 산출물과 진척 상황을 공유 합니다.
예를 들어 요기요 같은 온라인 음식 주문 서비스를 개발하는 프로젝트가 있다고 생각해 봅시다.
그 프로젝트 구조는 아래와 같을 겁니다.
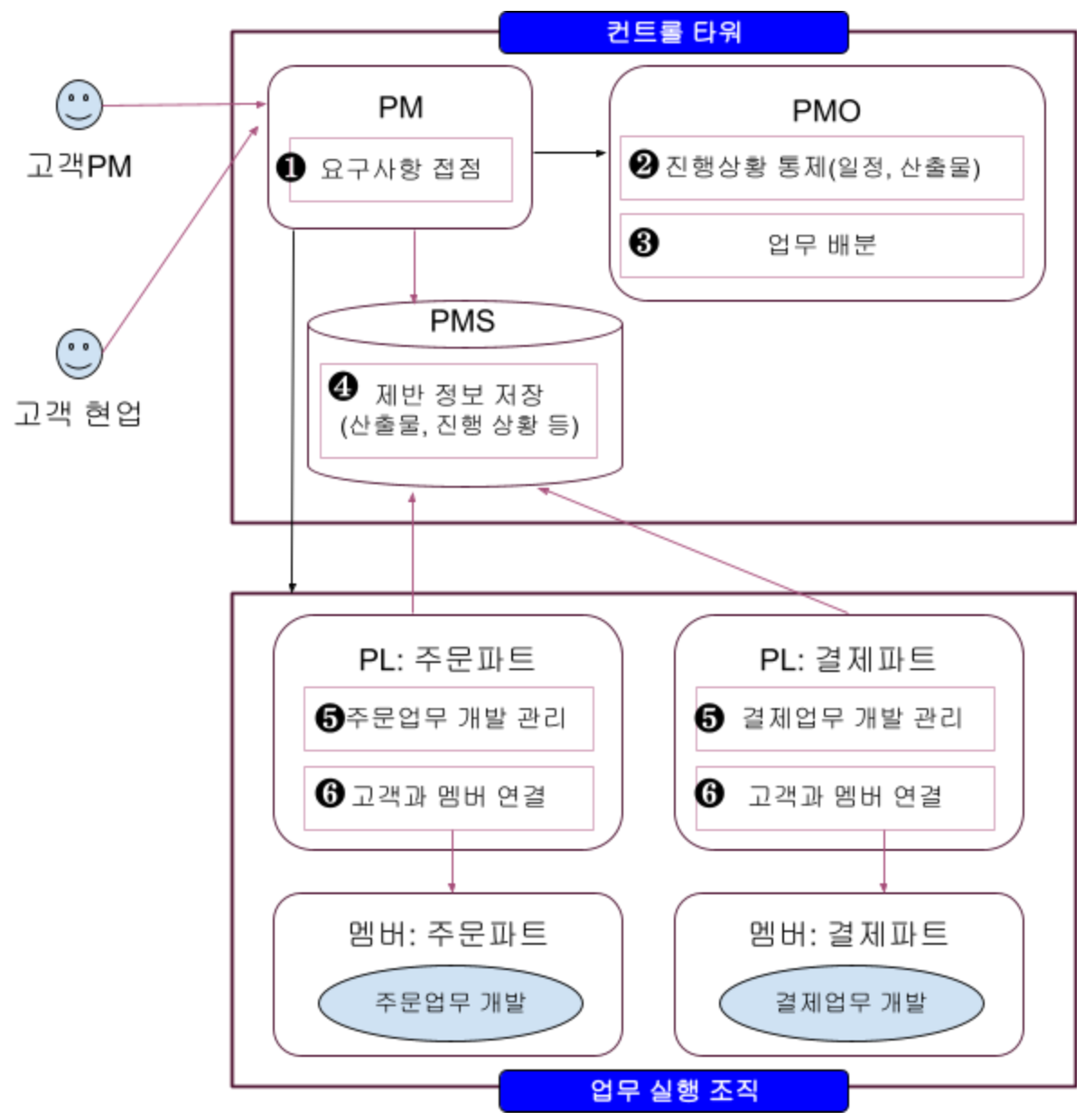
- 요구사항 접점: 고객PM이나 고객현업들은 신규/변경 요구 사항에 대한 모든 요청을 PM에게 함
- 진행상황 통제: 각 업무파트의 진행이 잘 되고 있는지 통제
- 업무배분: 신규/변경 요구사항에 대한 업무 배분을 수행
- 제반 정보 저장: 산출물과 제반 진행 상황에 대한 정보를 저장
- 주문/결제 업무 개발 관리: 각 파트리더는 업무 파트의 개발이 원활히 진행되는지 통제
- 고객과 멤버 연결: 고객의 요청에 맞는 개발 담당자 연결
이러한 프로젝트 관리 구조를 쿠버네티스 아키텍처를 구성하는 컴포넌트와 매치하면 아래와 같습니다.
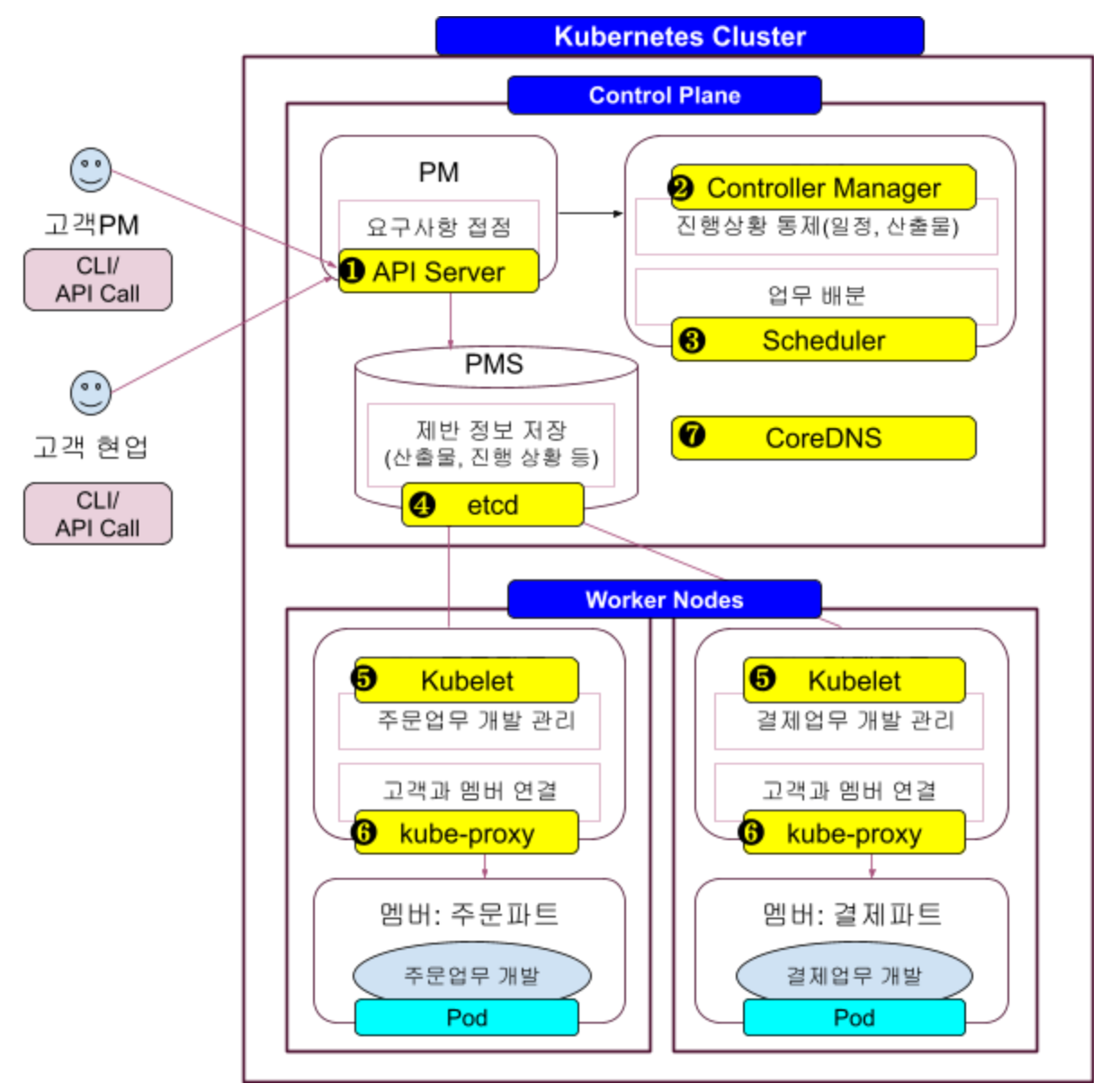
① API Server: CLI나 API호출을 통한 모든 요청을 수신하는 접점 서버
고객 PM이나 고객 현업들이 신규/변경 요구 사항에 대한 모든 요청을 PM에게 하듯이 쿠버네티스 클러스터로 들어오는 모든 요청을 받아 처리할 컴포넌트에게 전달하는 역할을 합니다.
② Controller Manager: 노드, 네임스페이스, 서비스, 파드를 통제하는 컴포넌트
PMO가 각 업무파트의 진행이 잘 되고 있는지 통제 하듯이 클러스터를 구성하는 노드, 네임스페이스, 서비스, 파드를 통제하는 컴포넌트입니다.
구체적으로는 4가지 역할을 합니다.
- Node Control: 노드가 다운되었을 때 통지와 조치
- Namespace Control: 새 네임스페이스 생성 시 기본 계정(Service Account)과 인증 토큰(Secret) 생성
- Service Control: 새 서비스 생성 시 파드의 주소를 갖고 있는 End Point 리소스 생성
- Pod Control: 지정된 파드 수가 항상 유지 되도록 통제
네임스페이스는 쿠버네티스 오브젝트를 목적별로 그룹핑한 구성 단위입니다. 조금 후에 좀 더 자세히 설명합니다.
End Point 리소스는 서비스 리소스가 파드를 연결하기 위한 리소스입니다. 서비스 리소스 설명 시 다시 설명 하겠습니다.
③ Scheduler: 파드를 어느 노드에 생성할 지 결정하는 컴포넌트
PMO가 신규/변경 요구사항을 어떤 업무 파트에 배정할 지 결정 하듯이 파드를 어떤 노드에 생성할 지 결정 합니다.
노드의 리소스(CPU/메모리) 사용 현황이나 배포 정의 Yaml에 정의된 명세를 고려하여 결정합니다.
④ etcd: 쿠버네티스 오브젝트 명세와 상태 정보를 저장하는 키-값(Key-Value) 구조의 데이터베이스
PMS에 산출물과 제반 진행 상황 정보가 저장되듯이 Ingress, Service, Pod 등의 쿠버네티스 오브젝트 명세와 상태 정보가 저장됩니다.
etcd에 모든 쿠버네티스 오브젝트의 정보가 저장되어 있기 때문에 쿠버네티스 클러스터를 백업할 때 이 etcd만 백업하면 됩니다.
⑤ kubelet: Worker 노드에 실행된 컨테이너가 잘 동작하도록 관리하는 컴포넌트
주문/결제 파트리더가 자신이 맡은 업무 파트의 개발이 원활히 진행되는지 관리하듯이 자신의 노드에 실행된 컨테이너가 정상적으로 동작하도록 관리하는 역할을 합니다.
⑥ kube-proxy: 쿠버네티스 외부 또는 내부와 파드를 연결해주는 네트워크 프록시 컴포넌트
파트리더가 고객의 요청에 맞는 개발 담당자를 연결해 주듯이 요청에 따른 파드를 연결해주는 역할을 합니다.
쉽게 말하면 Service Object와 Pod를 연결해주는 프록시입니다.
⑦ CoreDNS: 쿠버네티스의 서비스와 파드 주소를 관리하는 DNS(Domain Name Server) 컴포넌트
Ingress가 서비스를 연결하거나 서비스가 파드를 연결할 때 그 주소를 CoreDNS에서 찾아서 연결하게 됩니다.
PM, PMO, PMS가 각 업무파트를 관리 하듯이 API Server, Controller Manager, Scheduler, etcd는 각 Worker Node의 쿠버네티스 오브젝트들을 관리 합니다. 그래서 이 컴포넌트들은 컨트롤 플레인에 설치 됩니다.
파트리더가 자신의 업무 파트를 관리 하듯이 kubelet과 kube-proxy는 자신의 Worker Node에 배포된 컨테이너가 잘 동작할 수 있도록 관리합니다. 그래서 이 컴포넌트들은 Worker Node에 설치됩니다.
컨테이너 아키텍처에서 가장 중요한 부분 중 하나는 컨테이너 오케스트레이션(Orchestration)입니다. 컨테이너 오케스트레이션이란 컨테이너를 효과적으로 관리해주는 방식을 의미합니다. 컨테이너 오케스트레이션을 통해서 기업을 여러개의 어플리케이션과 서비스를 효율적으로 관리할 수 있습니다.
쿠버네티스는 현재 많은 기업이 채택하고 있는 컨테이너 오케스트레이션 툴입니다. 쿠버네티스를 활용하면 컨테이너 시스템 상에서 컨테이너 어플리케이션을 쉽게 배포하고 관리할 수 있습니다. 쿠버네티스는 기본적으로 Master Node와 Worker Node로 구성됩니다. Master Node는 전체 쿠버네티스 시스템을 관리하고 통제하는 컨트롤 플레인을 운영하는 노드입니다. Worker Node는 실제 배포하고자 하는 애플리케이션이 올라가는 노드입니다.
지금까지 설명한 쿠버네티스 아키텍처를 기술적으로 표현하면 아래와 같습니다.

어떠십니까? 이젠 이 그림만 봐도 각 컴포넌트가 무엇이고 어떤 역할을 하는지 아시겠죠?'cloud-controller manager'컴포넌트는 AWS, Azure, Google, IBM 등 퍼블릭 클라우드와의 연동을 통제하는 컴포넌트 입니다. 우리는 바닐라 쿠버네티스를 설치하였기 때문에 이 컴포넌트는 생성되지 않습니다.
위 [그림 3]에서 Kubernetes Control Plane이 올라간 노드가 바로 Master Node입니다. 여기서 컨트롤 플레인이라는 용어를 쓰는 이유는 전체 쿠버네티스 클러스터를 관리하고 필요한 여러가지 기능을 실행하는 역할을 하기 때문입니다.
kube-api-server는 쿠버네티스 클러스터에 필요한 API를 노출시켜주는 역할을 합니다. 그림에서 보시는 것처럼 구성요소들은 컨트롤 플레인에 있는 API 서버와 통신합니다. Kube-scheduler는 노드가 배정되지 않은 새로 생성된 파드를 감지하고, 실행할 노드를 선택합니다. kube-controller manager는 쿠버네티스 클러스터에서 동작하는 여러 컨트롤러들을 관리하는 역할을 합니다. cloud-controller manager는 클라우드 공급자(AWS, GCP, Azure 등)와 상호작용하는 컨트롤러를 관리합니다. 마지막으로 etcd는 모든 클러스터 데이터를 담는 Key-Value 저장소입니다.
Worker Node의 구성은 마스터와는 다릅니다. Worker Node는 컨테이너가 실행되는 컨테이너 런타임, 노드의 컨테이너를 관리하는 kubelet, 그리고 어플리케이션 구성 요소 간의 네트워크 트래픽을 분산해주는 kube-proxy로 구성되어 있습니다.
실제 각 컴포넌트가 쿠버네티스 클러스터에 존재하는지 확인해보겠습니다.
[root@osboxes work]# k get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-969848984-7s5h5 1/1 Running 0 3d22h
coredns-969848984-jnbwh 1/1 Running 0 3d22h
etcd-master 1/1 Running 0 3d22h
kube-apiserver-master 1/1 Running 0 3d22h
kube-controller-manager-master 1/1 Running 0 3d22h
kube-proxy-99rwj 1/1 Running 0 3d22h
kube-proxy-bnpdf 1/1 Running 0 3d22h
kube-scheduler-master 1/1 Running 0 3d22h위와 같이 API Server, Controller Manager, Scheduler, etcd, coredns가 파드로 실행되어 있습니다.
kubelet은 파드가 아닌 에이젼트로 설치되어 있어 나오지 않습니다.
kube-proxy는 두개가 실행되어 있습니다. 각각 컨트롤 플레인과 Worker Node에 실행된 것입니다.
2.2 클러스터Cluster, 컨텍스트Context, 노드Node, 네임스페이스Namespace 이해
Cluster는 Control Plane과 Worker Node들을 합쳐서 부르는 용어입니다.
Cluster는 컨트롤 타워 역할을 하는 Control Plane과 컨테이너가 실행되는 Worker Node로 구성되어 있습니다.
Worker Node는 줄여서 '노드'라고도 많이 부릅니다.
여기까지는 이미 이해하셨으리라고 생각합니다.
그럼 컨텍스트Context와 네임스페이스Namespace는 뭘까요?
Cluster와 노드가 물리적인 구성 단위라면 Context와 Namespace는 논리적인 구성 단위입니다.
Namespace는 쿠버네티스 오브젝트들을 논리적으로 묶은 구성단위입니다.
이미지 레지스트리와 Git 레지스트리의 Organization과 동일한 개념입니다.
Image Registry에서 유사한 성격의 Image Repositories를 묶어 Organization으로 관리했고, Git Registry에서는 유사한 성격의 Git Repositories를 묶어 Organization으로 관리했습니다.
쿠버네티스도 Ingress, Service, Pod같은 Object들을 유사한 목적별로 Grouping하여 Namespace라는 단위로관리 합니다.
예를 들어 Worker Node 2대에 주문서비스를 위한 파드 2개와 결제서비스를 위한 파드 2개를 배포한다고 생각해 봅시다.
주문과 결제는 성격이 다른 업무서비스 입니다. 파드끼리는 컨테이너화 되어 있기 때문에 상호 격리는 되어 있지만 성격이 다른 업무서비스가 섞여 있는 것은 관리하기 힘듭니다.
그래서 아래와 같이 업무 성격별로 네임스페이스를 나누고 네임스페이스별로 파드를 나누어 관리하는 것이 편합니다.
또한 네임스페이스별로 사용할 수 있는 CPU와 메모리 제한을 줄 수도 있습니다.
쿠버네티스 오브젝트들은 일부 오브젝트를 제외하고는 이렇게 네임스페이스별로 관리 됩니다.

컨텍스트는 연결 대상이 되는 Cluster, Namespace, User를 묶은 구성 단위입니다.
컨텍스트는 '상황이나 문맥'을 뜻하는 영어 단어입니다. 단어 뜻과 같이 상황별로 연결 대상 그룹을 나눈 것이 컨텍스트 입니다.
예를 들어 클러스터가 한국과 미국에 있고, 업무별로 관리하거나 운영하는 역할이 나뉘어져 있다고 생각해 봅시다.
이 경우 컨텍스트를 아래와 같이 4개로 나누어 관리할 수 있습니다.
사용하는 컨텍스트에 따라서 대상 Cluster, Namespace, User를 다르게 관리하는 것입니다. 유저에게는 해당 클러스터와 네임스페이스에 대한 적절한 권한 부여를 하여 보안을 보장할 수 있습니다.

컨텍스트 정의는 Kubernetes Config 파일에서 합니다.
설치 시, 컨트롤 플레인으로부터 Bastion Node의 '~/.kube' 디렉토리에 복사한 'config' 파일이 쿠버네티스 config 파일입니다.
아래 명령으로 쿠버네티스 config를 확인할 수 있습니다.
[root@osboxes work]# k config view
config 파일 내용을 보면서 컨텍스트에 대해 좀 더 확실하게 이해해 봅시다.
apiVersion: v1
clusters:
- cluster: >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> (5)
certificate-authority-data: DATA+OMITTED
server: https://169.56.70.197:6443
name: kubernetes
contexts: >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> (1)
- context:
cluster: kubernetes >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> (3)
user: kubernetes-admin >>>>>>>>>>>>>>>>>>>>>>>>>>>>>> (4)
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes >>>>>>>>>>>> (2)
kind: Config
preferences: {}
users:
- name: kubernetes-admin >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> (6)
user:
client-certificate-data: REDACTED
client-key-data: REDACTED- 컨텍스트 리스트를 이 항목 아래에 정의합니다.
- 현재 컨텍스트는 name이 'kubernetes-admin@kubernetes'이라는 의미입니다.
- 현재 컨텍스트의 대상 클러스터가 'kubernetes'입니다.
- 현재 컨텍스트의 접근 유저는 'kubernetes-admin'입니다.
- 대상 클러스터의 인증 토큰과 API Server 주소를 알 수 있습니다.
- 현재 컨텍스트의 접근 유저인 kubernetes-admin의 인증 토큰입니다.
※ 대상 네임스페이스가 없기 때문에 기본 네임스페이스인 'default'로 연결 됩니다.
쿠버네티스 config에 연결 대상 Cluster, Namespace, User를 정의한 컨텍스트를 추가하고, 그 컨텍스트를 현재 컨텍스트로 바꾸면 새로운 컨텍스트로 연결할 수 있습니다.
그 기술적 방법은 '14. 인증과 알백 방식의 인가'에서 설명 하겠습니다.
- source:
https://happycloud-lee.tistory.com/247
[쿠버네티스 쉽게 이해하기 2] 쿠버네티스 아키텍처
2. 쿠버네티스 아키텍처 쿠버네티스를 처음 설치 하시는 분들은 가이드 대로 따라하기는 하는데 왜 이 작업을 해야 하는지 이해가 안되는 게 있을 겁니다. 그 궁금증들은 앞으로 과정을 진행하
happycloud-lee.tistory.com
https://brunch.co.kr/@jehovah/27
[EKS 입문] Kubernetes 구성요소 1
포드, 레플리케이션 컨트롤러, 레플리카셋, 데몬셋 | Kubernetes Architecture 컨테이너 아키텍쳐에서 가장 중요한 부분 중 하나는 컨테이너 오케스트레이션(Orchestration)입니다. 컨테이너 오케스트레이
brunch.co.kr
'Dev > Kubernetes' 카테고리의 다른 글
| [Kubernetes] Liveness Probe - HTTP Request를 이용한 Health Check(HTTPGetAction) (0) | 2022.07.06 |
|---|---|
| [Kubernetes] Container Health Check (0) | 2022.07.06 |
| [Accordion] Kubernetes 기반의 통합 관리 솔루션 (0) | 2022.06.21 |